Опубликовано в (Yahoo Pipes) | автор splogmaster | 09-12-2008
Сразу определимся с терминологией: под парсингом html-страницы в Yahoo Pipes я понимаю граббинг (от слова grabber, т.е. схватить и утащить) всей html-страницы или ее части с последующим, по мере необходимости, преобразованием "схваченного".
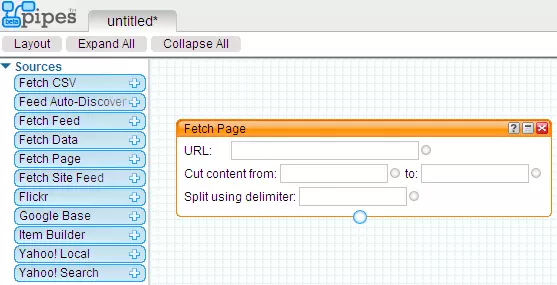
В общих чертах для задач парсинга в Yahoo Pipes нам нужны только 2 модуля: Fetch Page для граббинга и модуль Regex для преобразований с помощью регулярных выражений.
Модуль Fetch Page группы Source:
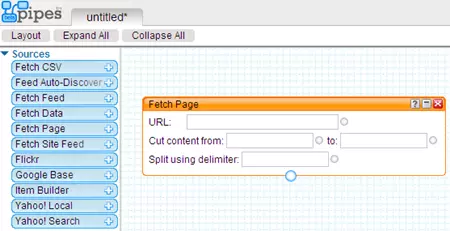
Поле URL - сюда вбивается адрес веб-страницы, которую мы собрались сграбить/спарсить; Поле Cut content from - если нам …
Опубликовано в (Yahoo Pipes, Контент) | автор splogmaster | 10-11-2008
Мысли у меня есть. Есть и частичные реализации. Пока что поделюсь только мыслями, попозже будут и реализации.
Под контентом я понимаю некое целое, составными частями которого являются текст, картинки и видео, - для буржуев возможно еще и подкасты, - вот таким я вижу контент для сплогов. Под генерацией контента я понимаю "найти все составные части и собрать их в единое целое".
И так, нам нужно сделать 3 вспомогательных параметрических трубы, каждая из которых будет выполнять свою определенную часть работы: первая труба будет на выходе выдавать нам картинку, вторая - видео, и третья - текст. В качестве входного параметра будет использоваться ключевой запрос, по которому нам нужен контент. Результирующая главная труба будет объединять результаты работы 3-х вспомогательных труб и на выходе выдавать RSS-фид со сгенерированным по нужному …
Опубликовано в (Yahoo Pipes) | автор splogmaster | 05-11-2008
Регулярные выражения - это механизм поиска определенных текстовых фрагментов в строке/тексте, основанный на использовании специальных шаблонов/масок/ или образцов/правил. Рекомендую для ознакомления с темой почитать о регулярных выражениях в википедии. Чтобы понять и увидеть на примерах, как это все работает, посетите следующие места:
Регулярные выражения. Синтаксис, примеры - именно эта статья стала для меня отправной точкой. Легкий язык, примеры, разжевывание - все что нужно для новичка; Синтаксис регулярных выражений - подойдет как справочник-таблица по специальным символам в регулярных выражениях; Регулярные выражения (шаблоны) - специальные символы, правила. Лишним не будет. Регулярные …