
Рабочая схема и пример граббера всего сайта в Yahoo Pipes
Опубликовано в (Yahoo Pipes, Контент) | автор splogmaster | 22-03-2009
Тэги: CSV, граббер, модуль
Продолжаю демонстрировать широчайшие возможности Yahoo Pipes в сплогостроительстве.
Сегодня я покажу алгоритм-схему трубы-граббера целиком всего сайта, будет конечно же и рабочий пример. И так, допустим, есть некий сайт-источник, весь контент с которого мы хотим позаимствовать для своего сплога. Обычно, создается труба, которая следит за обновлениями на сайте-источниками посредством мониторинга его RSS-ленты и дергает полные тексты новых постов, затем эти посты появляются на нашем сплоге, ну т.е. труба, которая из обычной RSS-ленты делает RSS-ленту с полными текстами новостей . Но остается актуальной задача полного граббинга всего сайта, не олько полседних постов, а всего начиная с амомго первого поста - в этом случае RSS-лента сайта-источника нам не поможет, ведь в ней нет информации обо всех постах на сайте, там только последние 10-25 постов. Будем парсить страницы сайта и выдирать ссылки на все его посты - вот такое некрасивое решение.
Для примера я взял первый попавшийся сайт типа блог razvlekuha.org.ua - типичный пример новостного сайта или сайта-каталога или блога на движке WordPress.
1. Перейдем на главную страницу подопытного сайта, внизу страницы находим постраничую навигацию - больше нам ничего и не нужно. В данном случае постраничная навигация реализована с помощью плагина WP-Pagenavi:
![]()
Ссылки на страницы имеют вид http://razvlekuha.org.ua/?paged=N где N - порядковй номер страницы. Смотрим сколько всего навигационных страниц на сайте - их 688 штук. Говоря программерским языком, на нужно реализовать цикл, в котором мы пробежимся по всем страница сайта и повыдираем с каждой страницы ссылки на посты, в итоге мы получим ссылки на все посты сайта. Для реализации цикла нам понадобится массив, в который мы занесем адрса/указатели на навигационные страницы сайта. Поскольку в Yahoo Pipes нет никакой поддержки работы с массивами, то нам придется прибегнуть к использованию внешних файлов с данными, в частности, массивом будет выступать .csv файл со списком порядковых номеров навигационных страниц сайта:
2. Теперь будем создавать трубу, она у нас будет всего одна, даже удивительно:) Я подробно покажу шаг за шагом как я делаю такие трубы-грабберы:
Перед созданием цикла на базе массива с порядковыми номерами навигационных страниц нам нужно поработать над распарсиванием лбой одной навигационной страницы. Возьмем для примера любую страницу (я взял http://razvlekuha.org.ua/?paged=2) и получим с нее ссылки на посты, размещенные на ней:
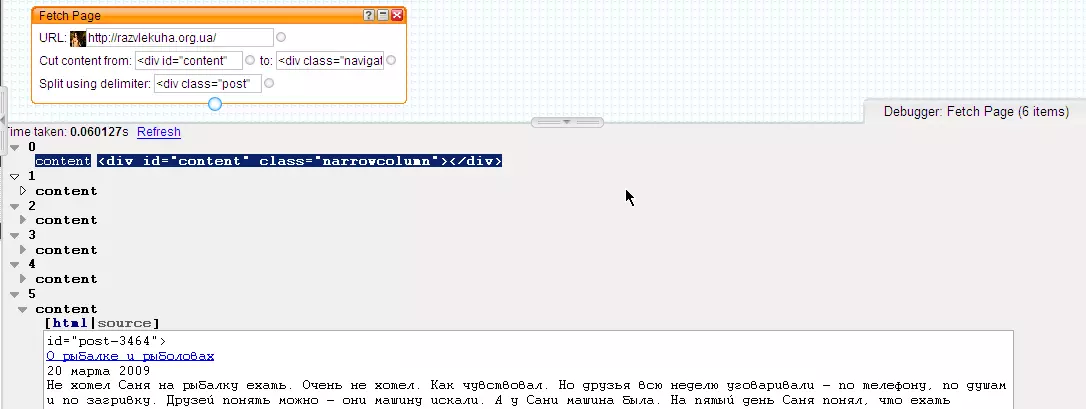
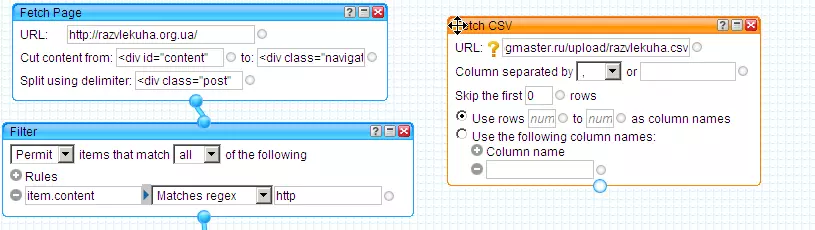
Для этого нам нужен модуль Fetch Page, тянуть данные мы будем только из той области страницы, где размещены анонсы постов. Всего на странице размещено по 5 анонсов постов, но, как видно на картинке, после отработки модуля Fetch Page у нас получается 6 item’ов - первый item (item c индексом 0) является побочным продуктом парсинга страницы и не содержит никакой ценной информации, поэтому от него мы избавимся следующим образом:
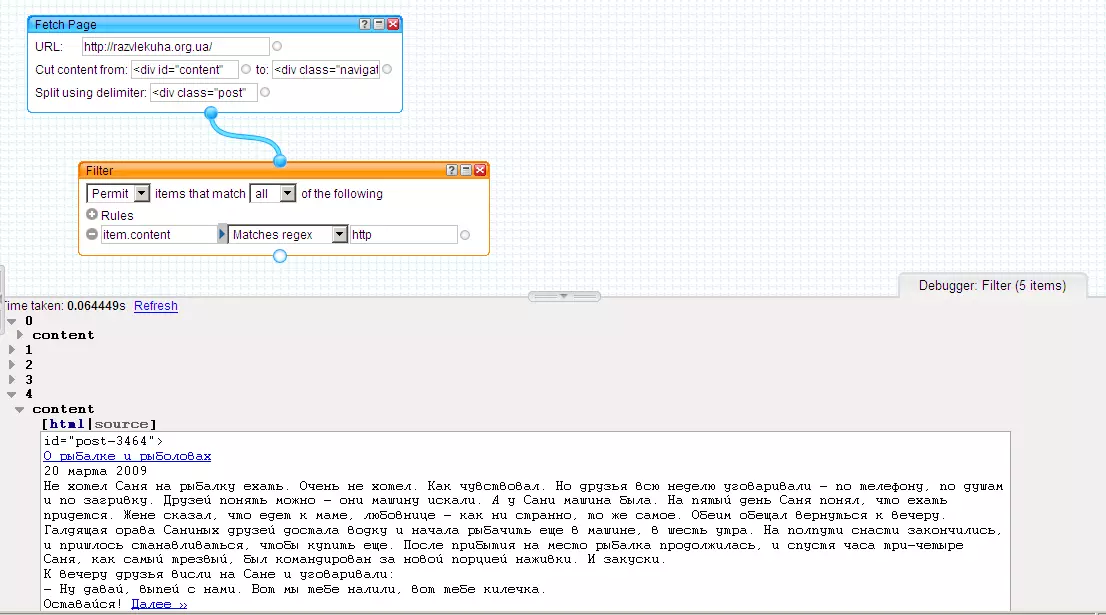
Вот теперь мы имеем 5 item’ов - ровно столько, сколько постов содержится на странице. В каждом item’е анонс одного поста, анонс включает в себя заголовок поста, ссылку на полный текст поста, краткое описание поста и категории/метки поста. Из анонса поста мы будем вырезать заголовк поста, ссылку на полный текст поста и категории поста. Делаем следующее:
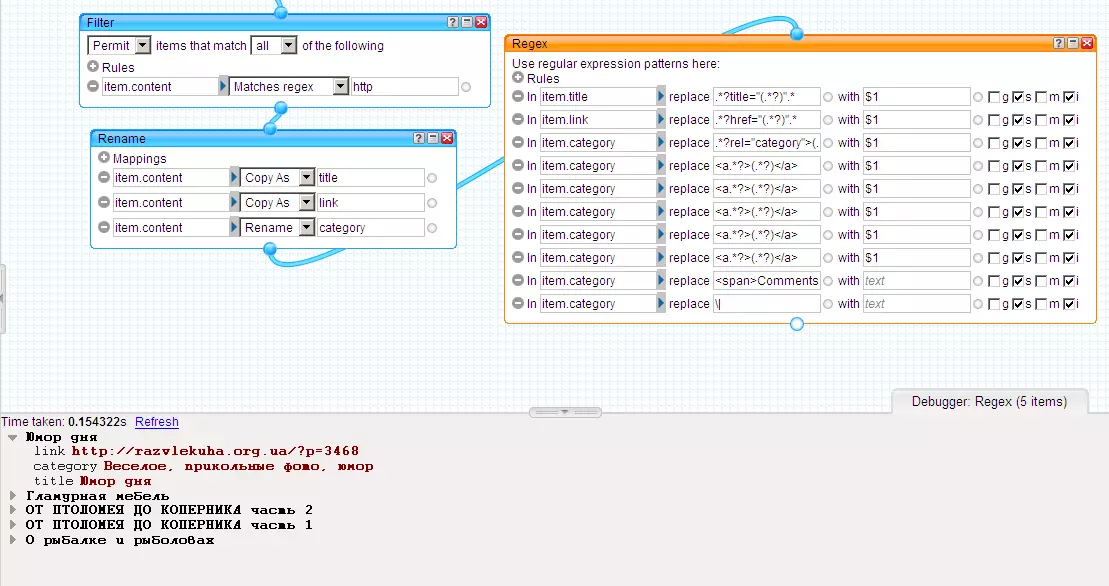
Основные сложности связаны с выделением всех категорий поста. В данном примере я взял только категории поста, но конечно же можно брать категории и метки поста - в конечном итоге это все равно превратится либо в только категории либо в только метки поста на сплоге.
Теперь, получив все необходимые данные о посте (заголовок, ссылка на страницу с полным текстом поста, категории поста) мы переходим к получению полного текста поста. Напомню, что постов у нас 5 штук. Используем цикл Loop и снова модуль Fetch Page:

Ну вот мы и получили полные тексты 5-ти постов, записали ихкак и следует в Description. На данном этаме наш трубопровод имеет следующий вид:

Вот теперь мы переходим к использованию массива с порядковыми номерами навигационных страниц. Вернемся к началу трубы, добавим модуль для подгрузки csv-файла, в котором содержится наш массив:
На сайте 688 страниц, на каждой странице расположено 5 постов - получается 3440 постов. Награбить 3440 постов за раз это слишком много для трубы, она просто зависнет. Поэтому введем в нашу трубу 2 параметра: первый параметр StartPos будет задавать стартовую позицию в массиве - те эелементы массива, которые находятся до StartPos будут отбрасываться; и второй параметр Count будет задвать количество элементов массива, которые будут обрабатываться трубой начиная со стартовой позиции StartPos. Например, для того, что бы награбить контента с 50 страниц начиная с 100-й страницы, нужно задать StartPos=100 и Count=50:

Ну и наконец, мы организуем цикл по навигационным страницам, а в конце трубы добавим недостающих для валидности rss-фида элементов:
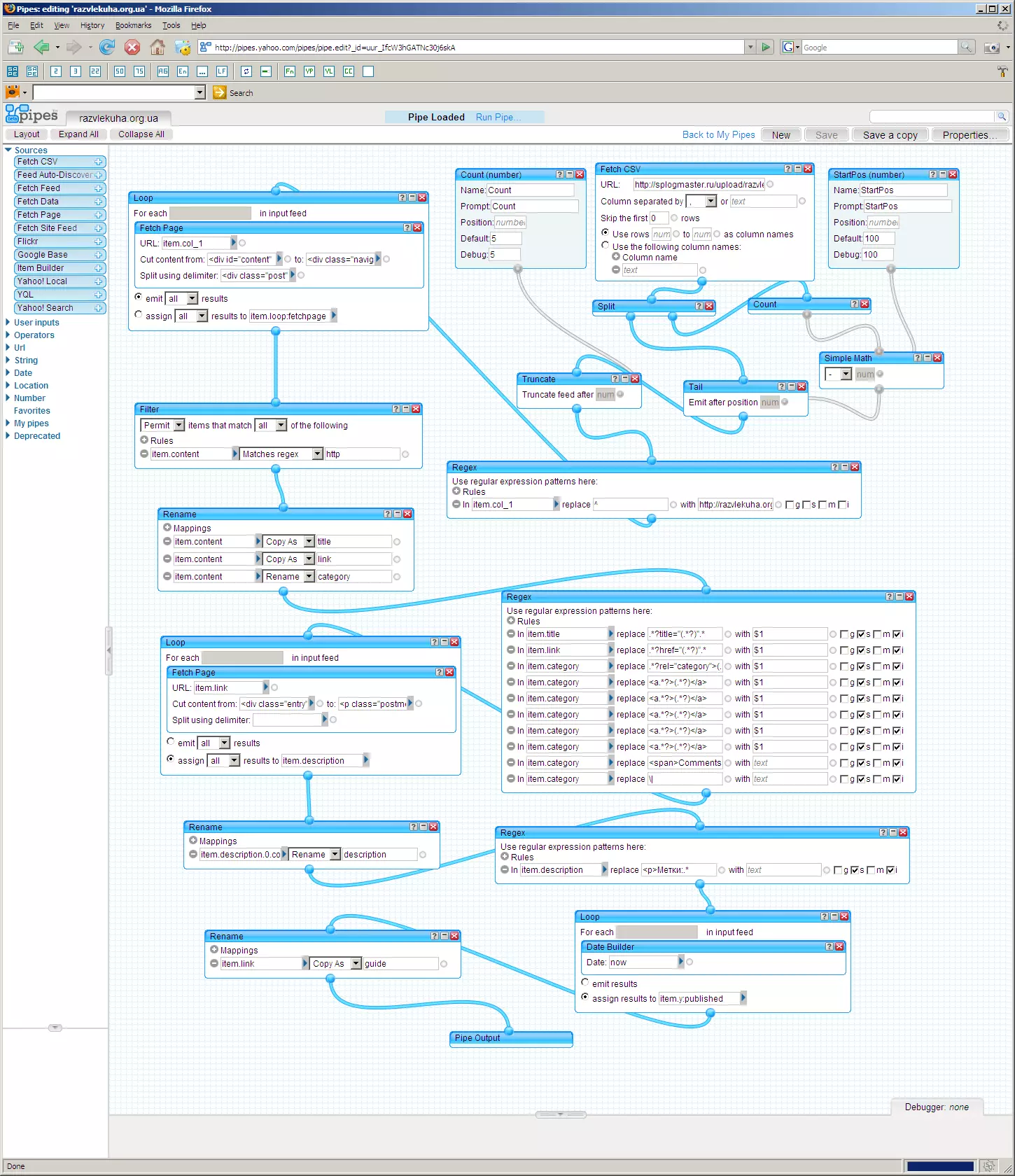
Все, труба готова. Исходник трубы . Созданная мной труба всего лишь наглядный пример общей схемы сборки трубы-граббера.
Московская компания качественно и аккуратно поможет осуществить офисный переезд, квартирный переезд и упаковку мебели.



Молоток, спасибо за труд, мне это потом пригодится, а пока почитаю другие посты старенькие ))))
привет
надеюсь вот связатся с тобой через комментарии
хочу создать 1000 блогов на блогспоте как ты говорил.
только нужна монетизация. адсенс не хочу.
ты монетезировал кодеками. я тоже хочу попробовать. только вот погуглила кодек партнерки - они не всех берут
сначала они долго проверяют трафик и вообще.
может у тебя есть инвайт к ним или может ты можешь помочь с регистрацией.
а какая у тебя была кодек партнерка?
тема кодеков, антиспайваре и т.п. уже давно умерла, да и англоязычные сплоги могут уйти в бан после первого же поста - плохой вариант для знакомства со сплогами на блоггере. т.е. помочь мне нечем и помогать нет в чем.
и 1000 сплогов это не то количество, когда нужно думать о монетизации, потому что монетизирвоать-то особо и нечего будет даже при более-менее удачном стечении обстоятельств. сначала нужно думать как сделать много, как вообще делать, как всем этим потом управлять, что делать с шаблонами, как в шаблоны скрыто вставлять коды рекламы/баннеров, чтобы не спалиться, потому что на блоггере бан очень часто идет по каким-то общим характерным для сплогов признакам внутри кода шаблона.
извините что не в тему, но почему не работает feedwordpress. При добавлении ленты:
Fatal error: Call to undefined function xml_parser_create() in /home/koolsex/domains/koolsex.ru/public_html/wp-includes/rss.php on line 1025
потому что функция xml_parser_create() содержится в специальном PHP расширении для работы с XML, и на твоем хостинге это расширение не включено.
автор те респект конечно,
но зачем с твоими знаниями этот пипс,
в php мог бы уже нереальную трубу сделать))