
RSS с полным текстом новостей в Yahoo Pipes
Опубликовано в (Yahoo Pipes, Контент) | автор splogmaster | 12-12-2008
Тэги: HTML, rss, Контент, парсинг, труба
Как известно, большинство RSS-лент содержат лишь анонсы новостей длиной в пару строчек - делать сплог на базе анонсов невыгодно, контента мало, к тому же эта RSS-лента скорей всего транслируется в куче RSS-каталогов, т.е. контент на таком сплоге будет очень неуникальным. Куда лучше делать сплог с полными текстами новостей - конечно же, это будет чистое заимствование контента с сайта-донора, но, поскольку брать контент с авторских сайтов и блогов в большинстве случаев мы не собираемся, то сайтами-донорами будут выступать сайты, которые в свою очередь сами заимствуют контент - поэтому без всяких зазрений совести можно педелывать RSS-ленты с анонсами новостей в RSS-ленты с полным текстом новостей.
Информацию об используемых модулях Yahoo Pipes можете получить в Описание модулей Yahoo Pipes
Для решения данной задачи в Yahoo Pipes нам понадобятся Основы парсинга html-страниц в Yahoo Pipes и модуль Loop. Подопытным кроликом будет некий блог Новости медицины, RSS-лента http://sarmednews.ru/?feed=rss2:
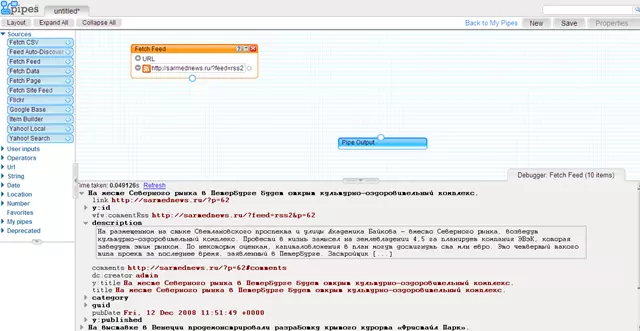
Мы вытащили на рабочий стол модуль Fetch Feed, указали в поле URL адрес RSS-ленты, и в Отладчике (Debugger) получили содержание этой RSS-ленты (кто не понимает, что он видит в Отладчике, читайте Структура формата RSS). Как видим, подэлемент Description содержит краткую версию новости (анонс) - нашей задачей является заменить содержимое подэлемента Description на полный текст конкретной новости. В подэлементе Link содержится ссылка на страницу с полным текстом новости - очевидно, нам нужно распарсить все страницы для каждой конкретной новости, получить полный текст новости, и заменить содержимое подэлемента Description на полученный контент с полным текстом новости. Для парсинга страниц нам нужен модуль Fetch Page. Для осущеествления цикла, в котором мы будем парсить все страницы, нам нужен модуль Loop:
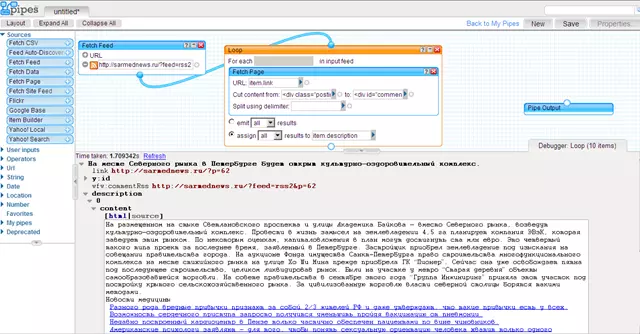
Что мы сделали: для организации цикла перетащили на рабочий стол модуль Loop, внутрь модуля Loop (т.е. внутрь или в тело цикла) поместили модуль Fetch Page, в котором в качестве параметра URL указали item.url - как я уже сказал, именно здесь хранится ссылка на страницу с полным текстом новости. Поскольку вся страница нам не нужна (нам нужен только пост/новость), путем анализа исходного HTML-кода любой страницы с полным текстом новости мы определили признаки начала и конца поста/новости, эти признаки мы прописали в модуле Fetch Page в полях Cut content from (вырезать контент с) и to (по). И последнее: в модуле Loop мы указали, куда будут сохранятся результаты парсинга: мы выбрали assign (это значит, что результат парсинга будет включен в исходный поток данных) и указали в result to куда конретно будут сохранены результаты парсинга - в нашем случае это item.desciption. В Отладчике мы видим результат нашего парсинга: в item.desciption.0.content (0.content автоматически добавляется внутрь item.description, такова особенность работы цикла Loop) содержится кусок вырезанного контента со страницы с полным текстом новости - как видим, кроме самой новости туда еще попал всякий мусор, в данном случае это ссылки на схожие записи. Мусор нужно убрать с помощью модуля Regex. Для этого нам нужно ознакомится с исходным HTML-кодом результата прасинга, который можно увидеть в Отладчике перейдя на соответствующую вкладку source:

Мы видим мусор перед самим текстом новости и мусор после текста новости, уберем его модулем Regex, сперва переименовав item.desciption.0.content в item.desciption с помощью модуля Rename:
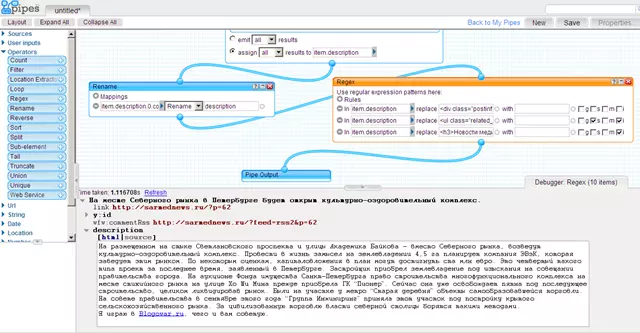
На этом, собственно, и все. Труба, которая из RSS-ленты с анонсами новостей делает RSS-ленту с полными текстами новостей, готова. Сравним исходную RSS-ленту http://sarmednews.ru/?feed=rss2 с полученной http://pipes.yahoo.com/pipes/pipe.run?_id=jlkgK1fI3RGlzYoVrbQIDg&_render=rss . А что делать с нормальной RSS-лентой написано в Создание сплогов на blogger.com (blogspot.com) и Создание сплога на движке wordpress .
Посмотреть исходный код созданной трубы и скопировать ее в свой аккаунт на Yahoo Pipes можно здесь http://pipes.yahoo.com/pipes/pipe.edit?_id=jlkgK1fI3RGlzYoVrbQIDg



Не ну у тебя совесть то есть нафига мой блог то так рекламировать, хоть бы ссылку поставил на меня нормальную
нафига мой блог то так рекламировать, хоть бы ссылку поставил на меня нормальную  а то счас все побегут мой блог дрючить и так он еще мелкий и не прокачаный.
а то счас все побегут мой блог дрючить и так он еще мелкий и не прокачаный.
вот те раз, а как это ты узнал, что я твой блог упомянул? специально же ссылки не делал. мистика какая-то. раз уж все равно не удалось скрыть факт эксперимента над твоим блогом, поставлю нормальную ссылку. и не бойся ты за свой блог, ничего ему из-за моего поста не будет, делать с такого контента сплог решится только идиот.
А с другой стороны пофиг посидел почитал твой блог, дельно пишешь и про Создание сплогов на blogger.com и про Создание сплога на движке wordpress. Есть что делное перенять, а контент с RSS в любом случае синонимайзером надо обработать ну я так по крайней мере думаю
ну я так по крайней мере думаю 
Ну за идиота спасибки а блог этот я сделал тоже ради эксперемента, разные способы поднятия тестирую
а блог этот я сделал тоже ради эксперемента, разные способы поднятия тестирую  поэтому то и мониторю часто, а контент ну уж извиняйте что в xap продали то и взял не самомуж сочинять
поэтому то и мониторю часто, а контент ну уж извиняйте что в xap продали то и взял не самомуж сочинять 
ну так я же про тебя и про твой блог ничего и не говорил:) у тебя не сплог - это раз, контент ты не скопипастил, а купил - это два. а вот сделать сплог из твоего блога это уже тупо.
Да эт понятно на самом деле, контент диз и т.д эт все наживное в крайняк можно и самому написать, а вот дельных способов поднять ТИЦ это надо еще поискать да погеммороиться, пока похвастать уменеем этот Тиц поднять не могу, вот и рыскаю в сети в поисках инфы, кстати про это пост был бы думаю многим интересен
с тицом сейчас вообще фигня творится. именно поэтому я работаю с трафиком и с гуглом, а не с тицем и с яндексом:) точнее я работаю сначала с гуглом, а после бана быстро переделываю сплог под яндекс:)
Слушай, идея суперская!
с новым постоянный читателем тебя
Только вот непонятно за что тебя Гугль банит? Уж с его то лояльностью к вебастеру… Яндекс то понятно и белых сайтов побанил кучу, че с него взять убогого. Но гугль хавает все. Поэтому я дивлен, что же там должно быть такое что бы в бан Гугля
Отличное руководство.. дурацкий вопрос - почему когда ты добавляешь рсс вид в фетч фид то у тебя там значек рсс появляется, а когда я добавляю - в лучшем случае знак вопроса.. если надо - могу сказать адрес вида.. заранее спасибо ))
вид значка зависит от фида. в большинстве случаев у меня тоже значок в виде знака вопроса - в любом случае какая к черту разница?:)
Опять я с дурацкими вопросами..
http://pipes.yahoo.com/pipes/pipe.edit#4lsax8Xq3RGPkhKXPxJ3A
почему дескриптион не заменяется? мозг уже сломал весь.. код подопытного изучил.. должно работать, а не работает..
[...] затем эти посты появляются на нашем сплоге, ну т.е. труба, которая из обычной RSS-ленты делает RSS-ленту с пол
Не понимаю я смысла этого пайпа
точнее сказать смысл то понимаю, эт для тех кто не может кодить, но смыслит хотябы в алгоритмах, но а если 1000 сплогов это нужно таких труб фигачить я пупею.
я для этого написал свой парсер на php, ему кидаю только адреса rss фидов хоть милион, а там она сам тянет полную новость с сайтов, сейчас хочу синонимайзер прикрутить к этой байде….
но вот ковырять пайпы я хз
объясни плз, как при помощи этих пайпов можно быстро напарсить туеву хочу контента с вагона сайтов?
или я что-то не понимаю
что значит “объясни”? показать пример - не покажу, подтвердить что “можно быстро напарсить туеву хочу контента с вагона сайтов” - можно. Да и зачем тебе это все?:) ты ж умеешь кодить, накодь себе мегапарсер всего интернета:)
ну твою иронию понимаю…
парсер всего интернета это конечно супер)))
пример показывать не нужно и сам вкурил уже, единственный плюс в пайпсах я думаю в том, что всю работу делает удаленный сервак пайпса, дабы не грузить свой сервер парсингом….
а так все это кодится на php не очень сложно
Привет! Спасибо за блог - очень интересно было узнать. Решил поэкспериментировать с трубами, но не могу понять - если я ставлю плагин feedWP, а источником делаю свою трубу - она будет обновляться постоянно или нет? Создалось такое ощущение, что инфа подтягивается один раз и усе…