
Основы парсинга html-страниц в Yahoo Pipes
Опубликовано в (Yahoo Pipes) | автор splogmaster | 09-12-2008
Тэги: Fetch Page, HTML, Regex, контент для сплогов, парсинг
Сразу определимся с терминологией: под парсингом html-страницы в Yahoo Pipes я понимаю граббинг (от слова grabber, т.е. схватить и утащить) всей html-страницы или ее части с последующим, по мере необходимости, преобразованием "схваченного".
В общих чертах для задач парсинга в Yahoo Pipes нам нужны только 2 модуля: Fetch Page для граббинга и модуль Regex для преобразований с помощью регулярных выражений.
Модуль Fetch Page группы Source:
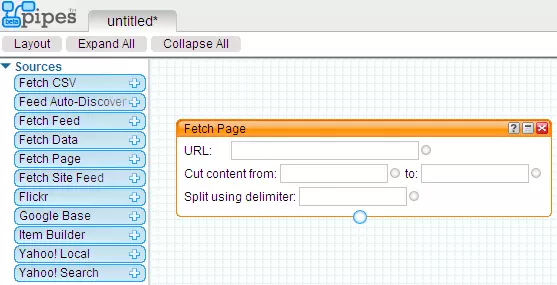
- Поле URL - сюда вбивается адрес веб-страницы, которую мы собрались сграбить/спарсить;
- Поле Cut content from - если нам не нужна вся страница, а только ее часть, то здесь мы указываем признак начала нужного нам куска, например, открывающий html-тег body;
- Поле to - здесь мы указываем признак конца нужного нам куска html-страницы, например, хкрывающий тег body;
- Поле Split using delimiter - по-умолчанию, т.е. при пустом значении этого свойства, весь сграбленый контент помещается в один item. Если же нам нужно разделить контент на части, например, мы парсим поиск картинок images.google.com - мы задаем этому свойству признак "разделения" контента на части, и получаем такое количество item‘ов, сколько картинок на странице с результатми поиска картинок, в каждом item‘е будет содержаться только одна картинка.
Модуль Regex группы Operators:

- Rules - это список правил, по которым модуль будет производить преобразования. Слева от слова Rules кнопка "+ в кружочке", под этой кнопка друга кнопка "- в кружочке" - кнопки для добавления/удаления правила;
- Поле In - здесь мы указываем в каком элементе item‘а мы будем производить преобразования, например, item.title;
- Поле replace - здесь указывается "что мы будем заменять";
- Поле with - здесь казывается "на что мы будем заменять";
- Чекбоксы g, s, m, i - включение/выключение модификаторов регулярных выражений. Включение можификатора g означает "глобальный" поиск, т.е. поиск всех значений; s - учитывание символа перевода каретки, справедливо только для длинных текстов; m - вроде бы что-то связанное с многострочностью, хотя я так и не понял как этот модификатор работает; i - нечувствительность к регистру.
Без знакомства с регулярными выражениями к модулю Regex лучше не подходить.
В заключение, небольшой пример. Распарсим главную страницу блога wpthemes.ru:
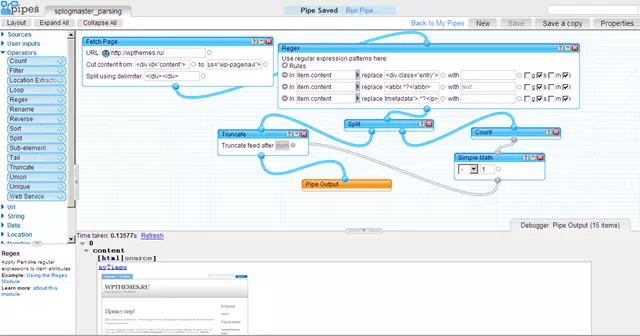
Исходный код трубы - здесь вы можете потрогать трубу руками, только сперва авторизируйтесь на Yahoo Pipes.
Что происходит в этой трубе-примере: модуль Fetch Page тянет контент с главной страницы подопытного блога, причем тянет он не всю страницу целиком, а только центральную часть, где располагается интересующий нас контент с анонсами новостей - для это мы указали признак начала и признак конца нужного нам участка страницы. Нам не нужны все ананонсы новостей в одной куче, т.е. в одном item‘е, поэтому мы задаем модулю Fetch Page признак разделения сграбленного контента на части. Затем мы переходим к преобразованию/чистке сграбленного контента модулем Regex - нам нужно подчистить верхушку первого item‘а (первое правило в модуле Regex), нам нужно убрать дату публикации постов (второе правило), нам нужно убрать информацию о каждом посте, где прописаны категории (третье правило). После этого нам нужно отрезать от полученного фида последний item, поскольку он у нас получился пустым (при парсинге части страницы обычно всегда приходится избавляться от мусора в начале части и мусора в конце части, потому что мы не можем сказать модулю Fetch Page "вырежь-ка мне кусок контента от начала первого поста и до конца последнего", нам приходится указывать четкие близлежащие ориентиры/признаки) - мы подсчитываем общее количество item‘ов в фиде, отнимаем единицу и берем из фида только полученное число item‘ов, начиная сверху.
С помощью Yahoo Pipes можно распарсить далеко не все html-страницы. Главной проблемой при парсинге является валидность html-кода страницы - Yahoo Pipes очень трепетно относится к кривому html-коду, и даже наличие простого js-скрипта для вызова попандера может помешать распарсить страницу. Вторым моментом является размер страницы: размер страницы не должен превышать 200 кб, иначе модуль Fetch Page откажется работать.



[...] решения данной задачи в Yahoo Pipes нам понадобятся Основы парсинга html-страниц в Yahoo Pipes и модуль Loop. Подопытным кроликом будет некий блог [...]
на выходе трубы у меня результат какой то странный получается - первого абзаца текста нет, и остальное непонятное
ПС кстати, если вы поставите плагин - подписки на комментарии (на емайл) - то это облегчит жизнь комментаторам и ваш диалог с ними
может пост обрезается с начала а не с конца ?
картинок нету в результате (они должны быть или как ?)
результат в виде рсс добавляю в читалку - вот и нету того, что надо, хотя в дебуггере трубы вроде нормал - нашел картинки и всё правильно
и всё правильно
я привел лишь пример парсинга страницы - это не пример создания полноценного rss с напарсенным контентом, поэтому результат в виду показывает пустоту. Вот тут https://splogmaster.ru/texnicheskoe-otstuplenie/struktura-formata-rss я писал о минимальном содержимом RSS, чтобы он проходил тест на валидацию.
Насчет плагина подписки на комментарии подумаю, спасибо за подсказку.